
[RedHat][vLLM]
人工智能的主要算力都是用在推理(Inference)方面,如何降低推理成本和提高推理效率,一直是業界最關心AI問題。
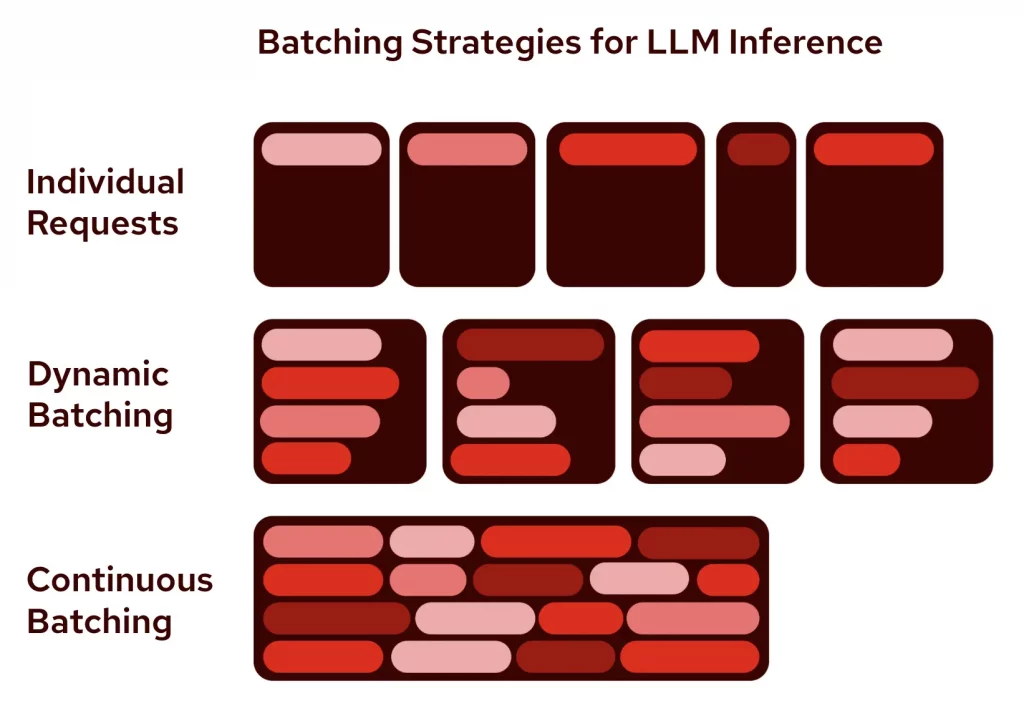
vLLM(Virtual Large Language Model)是加大柏克萊分校 2023 年開發LLM大語言模型推理框架並開源, 提供高輸送量的LLM推理並大大降低GPU記憶用量,迅速成為最受關注的開源項目。 Continue reading “Red Hat推出推理服務器 vLLM普及AI成本下降”

[RedHat][vLLM]
人工智能的主要算力都是用在推理(Inference)方面,如何降低推理成本和提高推理效率,一直是業界最關心AI問題。
vLLM(Virtual Large Language Model)是加大柏克萊分校 2023 年開發LLM大語言模型推理框架並開源, 提供高輸送量的LLM推理並大大降低GPU記憶用量,迅速成為最受關注的開源項目。 Continue reading “Red Hat推出推理服務器 vLLM普及AI成本下降”